Fun with Vector Databases
Posted on Thu 23 March 2023 in Python
Part 1. The best place to store you favourite kinds of data
(Quick link to repository for later)

A while ago I was reading up on how databases handle native geospatial datatypes; lat/lon pairs or 2 dimensional vectors. This then lead on to adding altitude and time, 3 and 4 dimensional vectors. How does the indexing and search work with these? For 2 and 3 dimensions many databases use R-trees.
What would you need to do if you had say 8, 15 or even 1024 dimensions? What sort of scifi nonsense is this?

What about n-dimensional vectors?
First lets show the main use case for storing n-dimensional vectors. In machine learning, especially with neural networks, you are are using numerical data. The learning models don't understand things like text, pictures, sound etc. We need a method transforming this unstructured data into numbers.
There are many, many methods to do this but here we are concerned with vectors, sometimes called embeddings. I'll talk through using text data, but the input can be anything unstructured (or even structured).
The embedding function takes in the sentence and outputs the vector.
"The cat sat on the mat" → [2.3, 4.5, 0.2]
What do these numbers mean? This may sound a bit woolly but they can be though of as 'concepts'. The first place could be how masculine/feminine the sentence is. Another value could be how much geography there is the sentence.
The classic example is shown below.
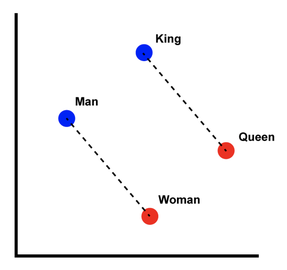
The vectors towards the lower right are more feminine, those to the upper left more masculine. The upper right, lower left is how royal an element is. If you added a queen point it would be feminine + royal and sit on the right hand side.
The great thing about these vector representations is that by their nature similar things will be close together in the space. So 'cat' will be near to 'dog' but far away from 'chocolate and peanut butter sandwich'.
Vectorizer function creation
Creating this mapping from text to embedding out of scope of this article but there is a good article here.
Word2vec is one of the earliest libraries I can remember. Things have moved on since then with the advancement of deep learning. We had models such as GloVe and BERT which enabled full sentences to be encoded. With this came new companies that provide apis to the larger cutting edge models. Companies like hugging face and openai.
Why vector databases?
Now that we have an abridged description of embeddings, why would you want to store them? Imagine you had a million stored documents, you are a solicitor maybe. You are working on a gnarly case about Jack Sparrow and piracy

You could do a text search for words like 'piracy' and 'sea' but you would miss a lot of documents. Words like 'marine' wouldn't be found and you may get returned some documents relating to software piracy. What you want is something that understands the context of what you are asking.
Now imagine all of your documents are stored as points in this big vector space. Your query text is also converted to a point in the space and we look for the documents that are nearest to this point and return them to the user - amazing idea eh!
There are many things you can do with this technology
- Find documents similar to a document or query text.
- Question / answering.
- Look for clusters in the space and use that to tag your data.
- Anomaly detection - why is this document far away from any others?
- Matching texts roles to resumes or dating.
- Deduplication of documents.
With the recent explosion in generative AI you should soon be able to the following
- Generate summaries of documents (you can already do this).
- Move the document around the space. Imagine being able to make a document less aggressive sounding or maybe make everything a bit more geography related.
- What is the difference between two documents.
Fast search
If we have millions of documents how can we efficiently search them? The R-tree doesn't scale to large numbers of vectors.
One of the most popular vector index types is HNSW (Hierarchical Navigable Small World). This trades insert time for improved query time.
The video below explains it really well
Part 2. Build a killer app using vector databases

As a nosy person one of my fave datasets is the Enron emails. Enron was a huge energy company that was ran by bad people and ultimately collapsed. You can get to know how bad the bad people where with the documentary. During the trial Enron was forced to release a ton of emails. For this article we'll build something to store and query the emails using our new found vector know-how.
I intend to write another article around using the Enron emails with Graph Neural Networks
Our cutting edge app is named "Enronalyse". Thank you GPT4 for coming up with the awesome name, you are the best!
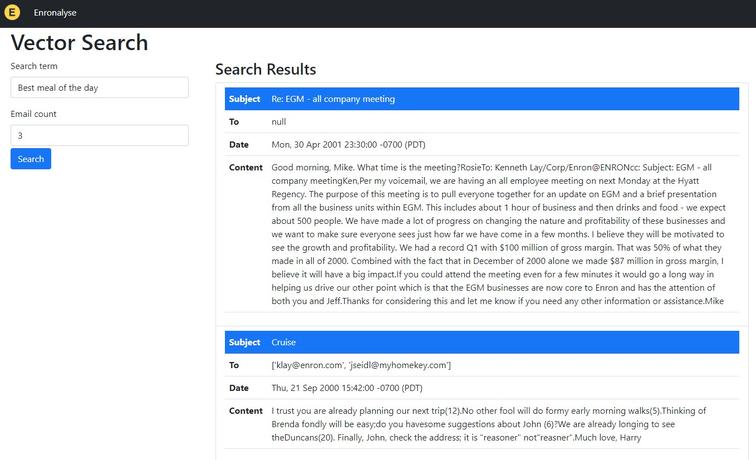
The repository is here
First pull the repo, pip install the requirements and create a .env file. The .env contains all of the settings relevant to your project (and saves me the worry of leaking my own secrets). I'll show which settings to add as we work through the app.
I'm using Weaviate as the vector database of choice. It has a really clean api and great documentation for getting you started.
Dataset
The first thing is to download the data and get it into a nice ingestible format.
The source can be found here, it's pretty big at 1.7Gb. Don't worry if you are still on dial up I've shared a sample of it pickled in the repo (emails_500.pkl)
We'll start at the top, chairman and CEO, Ken Lay. You only need to extract the enron_mail_20150507.tar.gz\enron_mail_20150507.tar\maildir\lay-k\ folder and put it somewhere accessible.
Add the EMAIL_FOLDER to your .env file, replacing the path with your own folder where you stored the emails. The **/*_ at the end tells python to filter all subfolders and ensure the files end in an underscore.
EMAIL_FOLDER="./data/lay-k/**/*_" # NonWindows
EMAIL_FOLDER="data\lay-k\**\*_" # Windows
Parse emails
The code for parsing emails is in the import/read_emails.py file. Its not that complex. Weaviate expects records formatted as a dictionary.
{
"email_id": 132,
"send_date": "Fri, 8 Dec 2000 07:49:00 -0800 (PST)",
"em_from": "a.b@enron.com",
"em_to": "c.d@enron.com",
"em_cc": None,
"subject": "a subject",
"content": "...",
}
You can run the this file and it will print out a count to show its all working. I'll come back to this later. But for now we have a array of email records with the main text in the content field.
Up and running with weaviate
There are 2 methods to obtain a running weaviate instance. Our app will work with either. The weaviate hosted method is much easier whereas using docker will give you a bit more understanding and a bit more scope to play.
1. Weaviate hosted
The easiest way is to use weaviate cloud services. Weaviate give you a free sandbox environment to evaluate the technology.
Sign up to create an account. Press the + button to create a new cluster.
| Setting | Value |
|---|---|
| Name | Anything |
| Subscription Tier | Free sandbox |
| Enable Authentication | No for now (don't upload any sensitive data) |
Press the create button and wait a couple of minutes for your instance to be created.
Add the url of the instance to the .env file. It should be the name you chose plus the weaviate network of the domain. i.e. if your instance name is abcde add the following
VDB_URL="https://abcde.weaviate.network"
You now have some cutting edge architecture at your disposal, how easy was that!
You'll also need a vectorizer, something to transform your sentences into vectors.
I'd recommend signing up to OpenAI. Have a look around, these are the people building the cutting edge.
Create yourself an access token here and add that token to the .env
OPENAI_API_KEY="*****"
Also have a look at Hugging Face. This site is amazing for hosting your own models and interacting with other pretty huge models. I went with openai for this article because the number of requests you could maker per second was more generous on the free tier.
2. Docker
This method allows you to run your own weaviate instance locally. You'll need to have docker installed.
The weaviate tutorial has an excellent piece on their website that generates a docker-compose file for you.
I've attached the one I'm using below
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: semitechnologies/weaviate:1.17.5
ports:
- 8080:8080
restart: on-failure:0
environment:
TRANSFORMERS_INFERENCE_API: 'http://t2v-transformers:8080'
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-transformers'
ENABLE_MODULES: 'text2vec-transformers'
CLUSTER_HOSTNAME: 'node1'
volumes:
- "D:/tmp/weaviate_vol:/var/lib/weaviate"
t2v-transformers:
image: semitechnologies/transformers-inference:sentence-transformers-multi-qa-MiniLM-L6-cos-v1
environment:
ENABLE_CUDA: '0'
You will need to change the first part of the volumes parameter to a folder on your local on your machine. This allows us to persist the database between sessions.
You can see there are 2 main containers, the weaviate database and the transformer. The transformer uses the multi-qa-MiniLM-L6-cos-v1 model. This is a smaller language model that produces vectors that are 384 elements in length.
For comparison the bert model has 768 and ada has 1024 elements. The larger the vector size the larger and richer the vector space. Though you then pay the cost of compute converting the sentences, search complexity and also the size of the db on disk. If you look into the weaviate tutorial it's fairly easy to switch out and use openAI, HuggingFace or Cohere apis to generate your vectors. The example below uses the openai api setup above.
To start the local instance its docker-compose up -d and docker-compose down to stop it.
The url to add to the .env will be localhost on port 8080
VDB_URL="https://localhost:8080"
Connect and create the class
Lets insert some data into the database. The code for this part is in the import/import_emails.py file.

I've created a VDB class that our database interactions talk to. The first part is the connection to the database. The connection handles authentication and various API keys but we are keeping it simple so just need the url from the .env file and the api key to the vectorizer.
def connect(self):
db_url = os.getenv("VDB_URL")
api_key = os.getenv("OPENAI_API_KEY")
self.client = weaviate.Client(
url=db_url, additional_headers={"X-OpenAI-Api-Key": api_key}
)
return self
The next part is where to store the data. Everything related to email uploading is in the EmailData class. Weaviate uses the notion of 'classes' (not the same as python classes) which are akin to tables. We are going to store everything in an 'Email' class. The smallest example of declaring the class just needs the class name and the vectorizer. Later on you can add things here like formally declaring the schema for the class.
class_obj = {
"class": "Email",
"vectorizer": "text2vec-openai"
}
The full create schema function looks like this
def create_schema(self):
class_obj = {
"class": "Email",
"vectorizer": "text2vec-openai"
}
db = VDB().connect()
# db.client.schema.delete_class("Email") # uncomment to delete table if needed
db.client.schema.create_class(class_obj)
If you are recreating the class you'll need to uncomment the delete line. Trying to overwrite will error. This is also useful for quickly emptying the table. The database will now have the email class and be ready to accept data.
Upload data
If this is your first run, its best to try with fewer emails. The get_email_data() function has a max_emails parameter. Set this to something like 20 while you play around with it.
Inserts are done in batches. It depends on your volume and size of the texts you are uploading. I found I had timeouts when uploading 3000+ full page documents (for another project) and batches of 50 worked well.
def insert_emails(self, email_data):
db = VDB().connect()
with db.client.batch as batch:
batch.batch_size=50
for email in email_data:
db.client.batch.add_data_object(email, "Email")
You can confirm the data has loaded at the url VDB_URL/v1/objects.
Once you are confident its working, recreate the email class and upload 500 messages.
Query the data
Now we come to the powerful part, using the vector search. Again this is all at the bottom of import/import_emails.py to play with.
Note, if you run this and get the error 'Model .... is currently loading ...'. You should wait a couple of minutes. It just means the instance is turned off due to it being free and weaviate are booting it.
The first part is what information we want returned. Just the main ones will do, as long as 'content' is there.
search_headers = ["email_id", "send_date", "em_to", "subject", "content"]
The next part is the nearText. This is our query text that gets turned into a point in the vector space and returns the emails nearby to it. We pass the query_term into the function.
nearText = {
"concepts": [query_term],
}
Then these are put together into a 'get' query. Also note the row_count of how many rows we want returned.
result = (
db.client.query.get("Email", search_headers)
.with_near_text(nearText)
.with_limit(row_count)
.do()
)
The full function is below.
def query(self, query_term, row_count=2):
db = VDB().connect()
search_headers = ["email_id", "send_date", "em_to", "subject", "content"]
nearText = {
"concepts": [query_term],
}
result = (
db.client.query.get("Email", search_headers)
.with_near_text(nearText)
.with_limit(row_count)
.do()
)
return result
Lets make like a journalist and look for those emails talking about the bad things. We'll search for the word 'criminality'.
eup = EmailData()
result = eup.query("criminality")
print(json.dumps(result, indent=4))
The first returned result is a bit of fluff, the second however is more interesting.
"subject": "Anonymous report on violations by senior Enron officials"
"content": "Please see attached file. I wish to remain anonymous...",
Scooby doo and his gang would be all over this. We don't have the attached file sadly. You can see though how this email didn't contain the word 'criminality' but due to the wonders of vector search the context is correct.

How about something a bit more far out, something more than a single word - "the captain of the titanic". The results are below.
"subject": "Cruise",
"content": "I trust you are already planning our next trip..."
"subject": "Dear Cruisers",
"content": " - CRUISE~1.DOC",
Emails about going on a trip on a cruise ship! Considering this is emails from the CEO of an energy company, these results are pretty good. You can add full documents of text in the search term, so you can search for emails that are similar an existing email. Just be careful of the token limit on the vectorizer.
Check the weaviate docs for other methods of tuning the search.
Build the app
Lets build an app that uses the super search functionality.
The fastapi tutorial that can be found on the fastapi site. It feels like a bit of a draw the owl moment with me dumping the complete app here all built.

This is not production code and more of a proof of concept. I've basically mashed some code from other personal projects together with the code above.
To run it ensure your .env has the VDB_URL and OPENAI_API_KEY filled in and working
EMAIL_FOLDER="***"
VDB_URL="https://***.weaviate.network"
OPENAI_API_KEY="***"
Pip install the requirements and then run uvicorn app.main:app --reload.
Open http://localhost:8000/ and be amazed by the slick UI.
Enter your search term, press the search button and boom, it renders your search results from the vector database.
You can see the swagger api docs at http://localhost:8000/docs. These allow you to test the endpoints without the UI.
Below are the main components of the app.
app/core/db - Utility class for connecting to the database.
app/api/v1/email - Handles the api requests for the search term.
app/models/email - Anything to do with the email model is here. Talks to the db class and cleans the input/output from it.
app/views/index - Handles rendering the front end.
static/ - images, css and js.
static/js/index - JQuery code to handle the search button press, api request and rendering the result.
templates - Jinja templates of html. Uses bootstrap.
(Quick link to repository)
There isn't much too it but I think it looks impressive.
Enronalyse++
Looking for ideas to expand the app?
- Add summaries of the emails using the hugging face summary api.
- Add moveTo and moveFrom query parameters so you can (de)emphasise parts of your query.
- Return the similarity scores.
- Plot the space in 3d.
- Formally declare the schema of the class.
- Add your own vectorizer and pass the vectors to the db.
- Add more classes.
- Add authentication to the db and app.
- Productionise the app - make tests, type hints, error handling and CI.
Take the concept app above and make it your own. I feel having these interesting projects are great for generating conversations during interviews.
Thank you for reading and if you have any questions or need any help please reach out to me.