Mario Environment API
Posted on Thu 24 May 2018 in yeah
Part 3. Build an api for the environment
Now that we can pull out information from the gameboy environment, why do we need to do this?
Reinforcement learning overview
I'll discuss the basic premise of reinforcement learning (RL). RL mimics how we humans learn things in the real world. We do an action and then we observe the world around us, we then learn how good the action was through feedback from the environment. i.e.
- I reach out to touch this radiator (action)
- The radiator burns my hand (environment)
- Pain in the hand (negative reward)
- I learn not to touch a hot radiator (policy)
- I may try again in the future though (exploration vs exploitation dilemma)
There are 2 main parts:
-
Agent
In real life this is us. In the mario game this is our learning script. It is the part that learns and makes decisions about what action to take next. -
Environment
The things external to the agent. The world around us or the gameboy emulator.
Next the information that pass between the agent and environment
-
State
The current state of the environment. Usually a minimal set of information as we don't need to know everything about the outside world. (I don't need to know the weather in Australia to drive my car in the UK) -
Action
The action the agent is taking, pressing the brake pedal, smiling, pressing right on the dpad etc. This may or may not produce a change in the environment -
Reward
How good was the change in the environment caused by our last action. This is what we want to maximise.
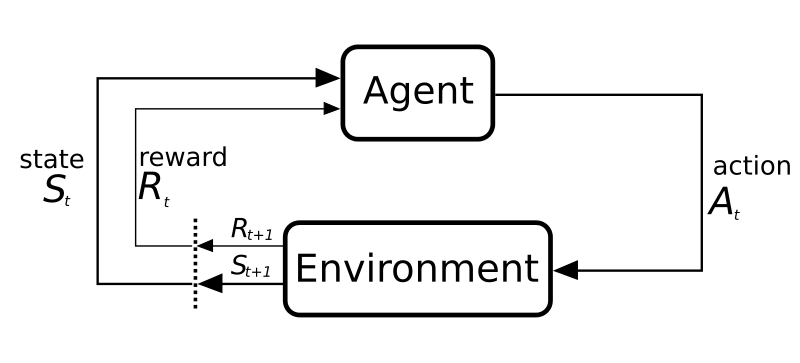
In our mario world each timestep can be seen as discrete rather than continous. We press a button and the gameboy moves forward one tick. There are RL methods to handle continuous time but discrete keeps things a lot simpler.
The policy (π) is what maps from each state (s) to the best action (a) to take
π(s) = a
The job of reinforcement learning is to determine this function and (usually) iteratively improve it.
So with all this in place, the environment is the emulator (plus our api wrapper) and the agent is our controlling script.
Build the API
On of the best ways of learning RL is through the open AI gym environments.
http://gym.openai.com/
The API they present is really simple and tidy and I've attempted to replicate it for our gameboy RL API
The first thing is to get create the evironment and set it back to it's start state. (The start state currently is a save state of mario at the start of level 1)
import gym
env = gym.make('SuperMarioWorld_GB')
env.reset()
We need a list of actions that the agent can do. We use ints instead of strings or objects as it keeps the whole RL process easier. I intend to have all 8 directions plus the buttons, but for now let's start small and get mario to run to the right. We'll have no action(0), left(3) and right(7).
You can get the list of possible actions using
actions = env.action_space
print(actions)
Prints (0, 3, 7).
Now for the real work, the step action. We pass it an action, internally it executes the action on the emulator, and we get back the new state of the environment and some reward. The step here is one execution of a fetch/execute cycle.
action = 1
obs, reward, done, info = env.step(action)
obsis the current state of the environment (after the action is executed)rewarda floating point value of how goodthe last action wasthe new state isdoneis a flag showing the episode is over. Mario has died or we reached the end of the levelinfois extra environment information. Not to be used for RL, more for debugging.
The obs will be the array of the screen display. We can already calculate marios death for the Done output.
Reward is a hard one to determine, how much do you reward, for what and what to punish and how severe. Note that it's not neccasarily numbers >1 are a reward and <1 are a punishment. They are just relative numbers on a number line. 5 is better than -1 which is better than -22.
I came up with the following for starters
- -100 mario death
- +5 we have a positive (right) velocity
Last thing is the policy. Keep it easy for starters with random actions. Mario meets brownian motion.
def random_policy(obs, actions):
return random.choice(actions)
Plumbing this all together gives us the environmental api.
The many versions of python
(I'm adding this extra part here it here as it's an important part of the environment.)
To maintain speed PyBoy runs on pypy2. Tensorflow and hence Keras, doesn't work on pypy.
Edit: There are patches now but at the time I built this there wasn't (https://github.com/tensorflow/tensorflow/issues/252))
This brings a host of problems
Running PyBoy on cpython2 is sloooooow. We're gonna do a lot of iterations and I have a finite amount of effort.
I tried upgrading PyBoy to python3 but couldn't get the SLD2 part working. It would run with the dummy window but not the viewable one.
I talked to the PyBoy author and he suggested RPC (way better than my idea of a small webserver!).
The idea is to have a seperate pypy2/gameboy environment and cpython3/keras environment, and have a communication channel between them. A quick look around and Pyro4 looked like a nice rpc library.
Our (pypy2) server is the PyBoy/open ai environment crafter above
The main method sets up the environment and exposes the class. This is all handled as a daemon in the background.
def main():
daemon = Pyro4.Daemon(port=9999)
tapi = MarioEnv(daemon=daemon)
uri = daemon.register(tapi, objectId='marioenv')
print('Server started: {}'.format(uri))
daemon.requestLoop()
print('exited requestLoop')
daemon.close()
print('daemon closed')
The class needs some decorators to make the magic happen
@Pyro4.expose
@Pyro4.behavior(instance_mode="single")
class MarioEnv:
"""
Environment to play super mario land on the gb
"""
In the (python3) client it's just a matter of giving Pyro4 the uri and the aooosh! we get the whole environment back.
def main(args):
env = None
try:
logger.info('Starting environment')
uri = "PYRO:marioenv@localhost:9999"
env = Pyro4.Proxy(uri)
env.start_pyboy()
# ......
except Exception as e:
logger.error('Failed to start environment')
logger.error(e)
traceback.print_exc()
sys.exit()
I'm sure there will be some python2 -> 3 shenanegans that crash everything but I haven't found them yet. Whatever protocol Pyro4 uses is pretty solid. The only problem I had was resetting the environment after each time mario died. It hung around and wasn't clearing up correctly.
Fixed with this piece of magic below
@Pyro4.oneway
def shutdown(self):
"""
Stop the environment
"""
print('shutting down...')
self.pyboy.stop(save=False)
self.daemon.shutdown()
I also talked to the PyBoy author about boosting the speed. We don't neccasarily need the gameboy to run in real time, as long as everythings syncs ok and we have enough mhz in our cores we should be able to increase the number of iterations. I figured that we don't need the full rendering, we only need the screen array. This would also give us some more clock cycles (profiling showed it as once of the slowest part) and also we could run it headless on a super aws gpu instance. Unfortunately the buffer is created right at the end of the render pipeline so it maybe trouble to run things headless - future todo.
We have mario running round in circles. He's dumb but has potential.